





Předpověď v TensorFlow je typicky provedena pomocí natrénovaného modelu. Nejprve vytvoříme a natrénujeme model na trénovacích datech, a poté jej použijeme k předpovězení výstupů pro nová vstupní data.
Níže je ukázka kódu, který vytváří jednoduchý model pro regresi, trénuje ho na nějakých datech a poté používá k předpovězení výstupů pro nová data:
import tensorflow as tf
from tensorflow import keras
import numpy as np
# Vytvoříme nějaká náhodná trénovací data
x_train = np.random.random((1000, 1))
y_train = 2 * x_train + np.random.random((1000, 1))
# Definujeme model
model = keras.models.Sequential([
keras.layers.Dense(1, input_shape=(1,))
])
# Kompilujeme model
model.compile(optimizer='adam', loss='mean_squared_error')
# Natrénujeme model
model.fit(x_train, y_train, epochs=10)
# Vytvoříme nějaká náhodná testovací data
x_test = np.random.random((300, 1))
# Použijeme model k předpovězení výstupů pro testovací data
y_pred = model.predict(x_test)
# Vytiskneme prvních 10 předpovězených hodnot
print(y_pred[:10])V tomto příkladu je model jednoduchá lineární regrese, která se snaží naučit se vztah mezi vstupem x a výstupem y ve formě y = ax + b, kde a a b jsou parametry, které model se snaží naučit během trénování. Poté, co je model natrénován, můžeme jej použít k předpovězení výstupů y pro nová vstupní data x.
Všimněte si, že v tomto případě jsou data generována náhodně, takže výsledky nemají žádný skutečný význam. V reálném scénáři byste měli nahradit x_train, y_train a x_test skutečnými daty.
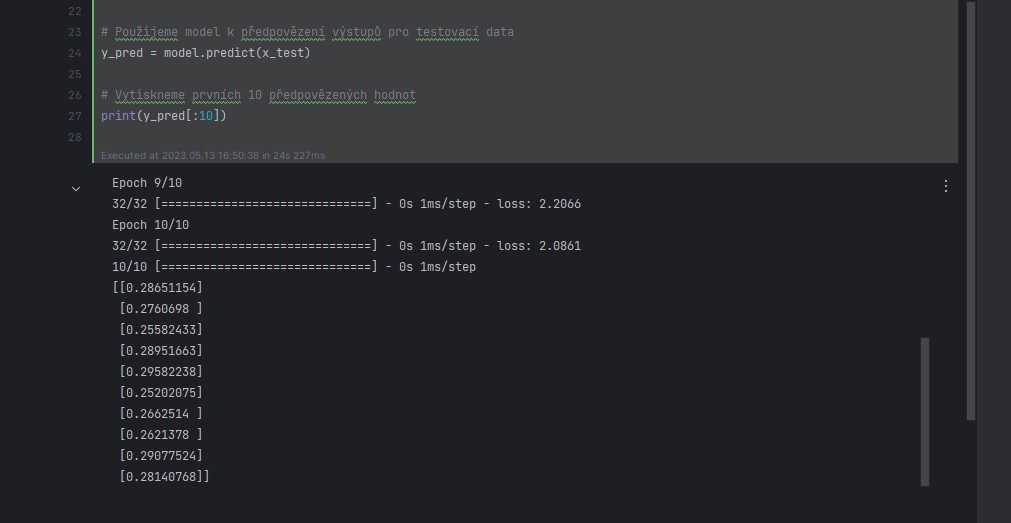
Výsledek je pole předpovězených hodnot pro vstupní testovací data. Každá hodnota v poli je předpovědí modelu pro příslušný vstupní bod.
Konkrétně, v tomto případě máme model regrese, který předpovídá jednu hodnotu pro každý vstupní bod. Takže vstupní bod x_test[0] odpovídá předpovězené hodnotě y_pred[0], vstupní bod x_test[1] odpovídá předpovězené hodnotě y_pred[1], atd.
Výsledek [0.32610345] je tedy předpovězená hodnota pro první vstupní bod v testovacích datech, [0.7131642] je předpovězená hodnota pro druhý vstupní bod, atd.
Tato předpověď je založena na interních parametrech modelu, které byly naučeny během fáze trénování na základě trénovacích dat.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zanechte komentář