






Tento model dokáže doporučovat produkty uživatelům na základě jejich předchozího chování.
Představme si, že máme e-commerce web a chceme doporučovat produkty uživatelům na základě jejich předchozího chování. Mohli bychom využít knihovnu TensorFlow pro vytvoření doporučovacího systému.
Jedním z populárních přístupů k doporučovacím systémům je metoda collaborative filtering, kde se systém učí předpovídat hodnocení uživatele pro produkt na základě hodnocení ostatních uživatelů.
Představme si, že máme dataset obsahující uživatele, produkty a hodnocení uživatele pro daný produkt. Dataset by mohl vypadat následovně:
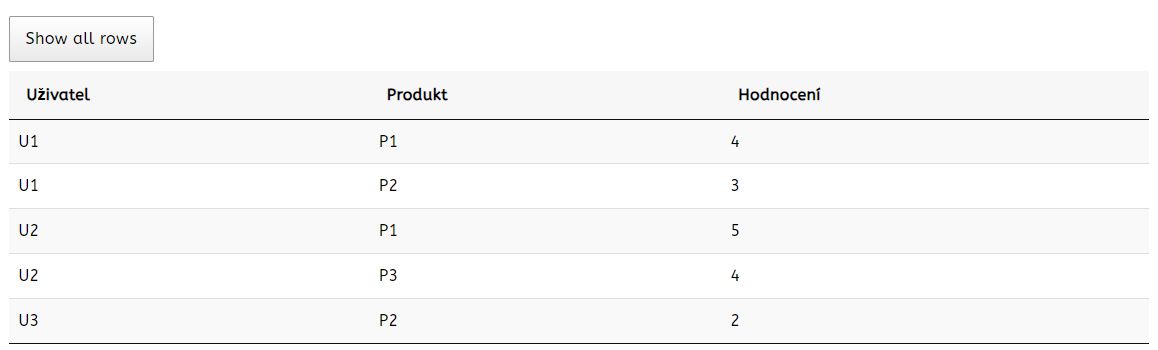
Pak můžeme vytvořit matici interakcí mezi uživateli a produkty, kde řádky odpovídají uživatelům, sloupce odpovídají produktům a hodnoty v matici odpovídají hodnocením uživatelů pro daný produkt.
Zde je jednoduchý příklad, jak vytvořit doporučovací systém pomocí TensorFlow. V tomto příkladu použijeme funkci tensorflow.keras.layers.Embedding pro vytvoření embeddings pro uživatele a produkty, a pak využijeme Dot pro výpočet skóre.
import numpy as np
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Embedding, Input, Flatten, Dot
from tensorflow.keras.optimizers import Adam
# Představme si, že máme 1000 uživatelů a 500 produktů
num_users = 1000
num_products = 500
# Vytvoříme model
user_input = Input(shape=(1,))
product_input = Input(shape=(1,))
user_embedding = Embedding(num_users, 50)(user_input)
product_embedding = Embedding(num_products, 50)(product_input)
user_embedding = Flatten()(user_embedding)
product_embedding = Flatten()(product_embedding)
rating = Dot(axes=1)([user_embedding, product_embedding])
model = Model(inputs=[user_input, product_input], outputs=rating)
model.compile(optimizer=Adam(), loss='mean_squared_error')
# Teď bychom natrénovali model na našich datech
# Představme si, že máme následující data
user_ids = np.array([0, 1, 2, 3, 4])
product_ids = np.array([0, 1, 2, 3, 4])
ratings = np.array([5, 4, 3, 2, 1])
model.fit([user_ids, product_ids], ratings, epochs=10)
V tomto příkladě jsme použili funkci `Embedding` pro vytvoření „embeddings“ pro uživatele a produkty. „Embedding“ je způsob, jak převést kategorické proměnné na vektorovou reprezentaci, která může být použita v neuronových sítích. Poté jsme použili funkci `Dot` pro výpočet skóre mezi uživatelskými a produktovými „embeddings“. Toto skóre představuje předpovězené hodnocení uživatele pro daný produkt. Model pak trénujeme na našich datech (user_ids, product_ids a ratings). V tomto jednoduchém příkladě jsme použili malý dataset, ale v praxi bychom měli mít mnohem větší dataset s hodnoceními od mnoha uživatelů pro mnoho produktů.
Tento kód je základním příkladem, jak vytvořit doporučovací systém pomocí TensorFlow. V praxi bychom mohli vylepšit tento model různými způsoby, například přidáním dalších vstupů do modelu (např. věkové skupiny uživatelů, kategorie produktů atd.), použitím komplexnějších architektur neuronových sítí nebo využitím dalších technik jako je například „dropout“ pro předcházení přeučení.
Tento kód může být prakticky využit v jakémkoliv kontextu, kde potřebujete doporučovací systém. Například:
E-commerce: Doporučovací systémy jsou klíčové pro většinu velkých e-commerce platforem, jako je Amazon nebo Alibaba. Mohou být použity pro doporučení produktů uživatelům na základě jejich předchozího chování nebo preferencí.
Streamingové služby: Platformy jako Netflix nebo Spotify také intenzivně využívají doporučovací systémy pro doporučení filmů, televizních seriálů nebo hudby uživatelům.
Sociální média: Facebook, Twitter a další sociální média využívají doporučovací systémy pro doporučení přátel, stránek, tweetů a dalšího obsahu.
Co se týče praktického využití kódu, po trénování modelu můžete použít metodu predict k predikci hodnocení pro konkrétní dvojici uživatele a produktu. Pokud chcete doporučit N produktů konkrétnímu uživateli, můžete predikovat hodnocení pro uživatele a všechny produkty, a pak vybrat N produktů s nejvyššími predikovanými hodnoceními.
Příklad jak to může vypadat:
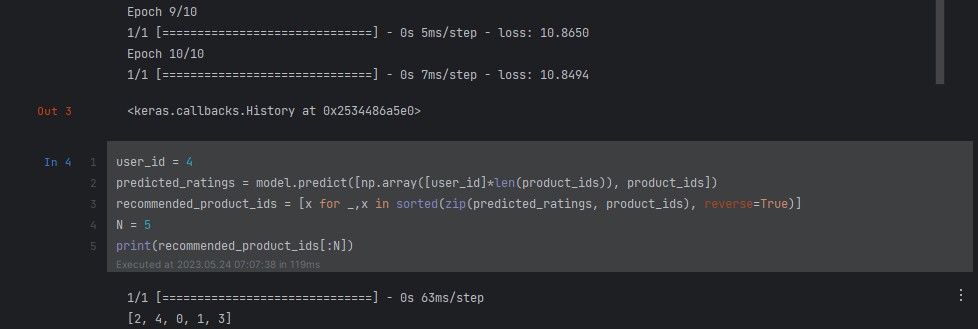
# ID uživatele pro kterého chceme doporučit produkty
user_id = 5
# Vypočítáme predikované hodnocení pro všechny produkty
predicted_ratings = model.predict([np.array([user_id]*len(product_ids)), product_ids])
# Seřadíme produkty podle predikovaných hodnocení
recommended_product_ids = [x for _,x in sorted(zip(predicted_ratings, product_ids), reverse=True)]
# Vrátíme N nejlépe hodnocených produktů
N = 5
print(recommended_product_ids[:N])
Tento kód předpokládá, že product_ids je pole všech ID produktů, které máme k dispozici, a model je náš natrénovaný model. Toto je jen zjednodušený příklad a v praxi by bylo potřeba přidat další chybové kontroly a optimalizace.
- collaborative filtering
- collaborative filtering anomaly detection
- collaborative filtering cold start problem
- collaborative filtering datacamp
- collaborative filtering for implicit feedback datasets
- collaborative filtering in amazon
- collaborative filtering movie recommender system
- collaborative filtering paper
- collaborative filtering python
- collaborative filtering recommender systems
- doporučovací systém
- python
- tensorflow











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zanechte komentář