





V Pythonu lze vytvořit mnoho užitečných SEO nástrojů. Jeden takový nástroj může být skript, který kontroluje on-page SEO faktory jednotlivých stránek na webu. Pro tento účel můžeme použít knihovny requests pro stahování obsahu stránek a beautifulsoup4 pro parsování HTML a získání potřebných dat.
Tento skript vytváří jednoduchou GUI aplikaci, která umožňuje uživateli zadat URL pro analýzu a poté zobrazuje výsledky analýzy ve výstupním textovém poli.
Tento skript kontroluje mnoho dalších SEO faktorů, včetně kontrol dob načítání stránky, kontroly, zda stránka používá HTTPS, kontroly, zda stránka má robots.txt a sitemap.xml, kontroly počtu interních a externích odkazů, kontroly nadpisů různých úrovní (H1-H6), kontroly, zda stránka má favicon, a kontroly meta tagů.
from bs4 import BeautifulSoup
import requests
import tkinter as tk
from tkinter import messagebox
from urllib.parse import urlparse, urljoin
import time
def seo_analyze():
# get value from form
url = url_entry.get()
# check if URL was entered
if not url:
messagebox.showerror('Error', 'Please enter a valid URL.')
return
start_time = time.time()
response = requests.get(url)
load_time = time.time() - start_time
soup = BeautifulSoup(response.text, 'html.parser')
# Check title
title_tag = soup.title.string if soup.title else "No title found."
# Check meta description
description_tag = soup.find('meta', attrs={'name': 'description'})
description = description_tag["content"] if description_tag else "No description found."
# Check H1-H6 tags
h_tags = [len(soup.find_all(f'h{i}')) for i in range(1, 7)]
# Find internal and external links
links = soup.find_all('a', href=True)
int_links_count = len([urljoin(url, link['href']) for link in links if urljoin(url, link['href']).startswith(url)])
ext_links_count = len(links) - int_links_count
# Check if website has robots and sitemap
robots_exists = 'Yes' if requests.get(urljoin(url, '/robots.txt')).status_code == 200 else 'No'
sitemap_exists = 'Yes' if requests.get(urljoin(url, '/sitemap.xml')).status_code == 200 else 'No'
# Check if website is using HTTPS
scheme = urlparse(url).scheme
is_https = 'Yes' if scheme == 'https' else 'No'
# Check metadata
metadata = soup.findAll('meta')
meta_info = ['No' for _ in range(4)]
for meta in metadata:
if 'name' in meta.attrs:
if meta.attrs['name'] == 'viewport':
meta_info[0] = 'Yes'
if meta.attrs['name'] == 'robots':
meta_info[1] = 'Yes'
if 'rel' in meta.attrs:
if 'canonical' in meta.attrs['rel']:
meta_info[2] = 'Yes'
if 'property' in meta.attrs:
if 'og:image' in meta.attrs['property']:
meta_info[3] = 'Yes'
# Check favicon
has_favicon = 'Yes' if soup.find('link', rel = 'icon') else 'No'
# Number of images without alt attribute
images = soup.find_all('img')
img_count = len(images)
img_no_alt_count = sum(1 for img in images if not img.get('alt'))
output_text.delete(1.0, tk.END)
output_text.insert(tk.END, f'URL: {url}\n')
output_text.insert(tk.END, f'Title: {title_tag}\n')
output_text.insert(tk.END, f'Description: {description}\n')
output_text.insert(tk.END, f'Load time: {load_time}\n')
output_text.insert(tk.END, f'Using Https: {is_https}\n')
output_text.insert(tk.END, f'Robots.txt exists: {robots_exists}\n')
output_text.insert(tk.END, f'Sitemap.xml exists: {sitemap_exists}\n')
output_text.insert(tk.END, f'Has favicon: {has_favicon}\n')
output_text.insert(tk.END, f'Has viewport meta tag: {meta_info[0]}\n')
output_text.insert(tk.END, f'Has robots meta tag: {meta_info[1]}\n')
output_text.insert(tk.END, f'Has canonical link: {meta_info[2]}\n')
output_text.insert(tk.END, f'Has OpenGraph protocol image: {meta_info[3]}\n')
for i in range(6):
output_text.insert(tk.END, f'H{i+1} tags count: {h_tags[i]}\n')
output_text.insert(tk.END, f'Internal links: {int_links_count}\n')
output_text.insert(tk.END, f'External links: {ext_links_count}\n')
output_text.insert(tk.END, f'Number of images: {img_count}\n')
output_text.insert(tk.END, f'Images without alt attribute: {img_no_alt_count}\n')
window = tk.Tk()
window.title("SEO Analyzer")
url_label = tk.Label(window, text="URL")
url_label.pack()
url_entry = tk.Entry(window)
url_entry.pack()
analyze_button = tk.Button(window, text="Analyze", command=seo_analyze)
analyze_button.pack()
output_text = tk.Text(window)
output_text.pack()
window.mainloop()
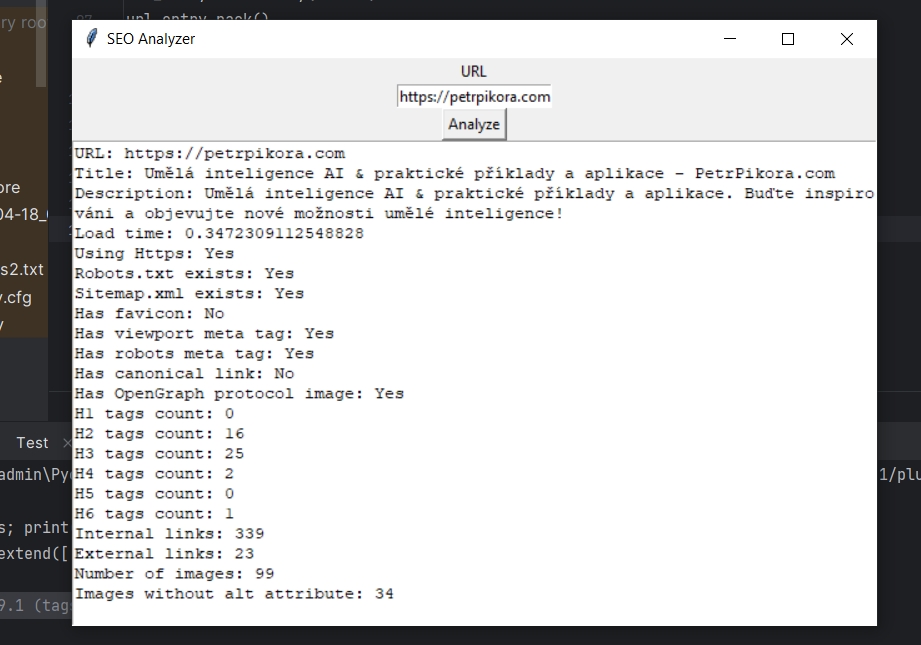
Zde je ukázka spuštěného skriptu:











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zanechte komentář